
开放环境的机器学习是目前的研究难点与热点,是算法落地的关键之一。其中,开放环境的多智能体强化学习与人智协同方向需要智能体与各种多样甚至是未见的队友策略进行高效协作。为了达成这一目标,主流方法在训练阶段生成若干队友策略与智能体配对训练以提高智能体的协作能力。然而,以往方法尝试以队友策略为中心解决问题,而无法高效并有保证地生成多样的队友策略,进而导致智能体在开放环境中与未见队友的协作能力有限,阻碍了该方向的发展。
基于此,南京大学与南栖仙策团队合作提出了一种面向任意队友的高相容性协作算法(Multi-agent compatible policy learning, Macop),成功发表在DAI'2023会议上,并获得唯一最佳论文奖(Best Paper Award)。这一算法可以应用在多智能体强化学习与人智协同领域,有效地增强了智能体与多样甚至未见的智能体队友或人类队友进行协同的能力,推进了集群协同的有无人系统在开放现实世界的落地应用。
以往队友生成与训练智能体方法的局限性
经典的协作多智能体强化学习方法,假设训练阶段与测试阶段,智能体都与相同的队友策略进行协作,这些方法致力于提升一个固定且封闭的多智能体系统的协作性能。然而,真实的协作场景往往是开放的,也就是说智能体需要与各种多样甚至是训练阶段没有遇到过的队友进行协作,例如游戏AI需要与实时匹配到的人类玩家协作、自动驾驶智能体需要与路面上的人类司机协作等等。为了赋予智能体在这些开放的场景中与多样甚至未见队友协作的能力,一种可行的方法是在训练阶段就使得智能体学会与尽可能多样的队友协作。

开放协作场景中,智能体需要与多样甚至未见队友协作
基于此,研究者提出了例如虚拟博弈[1]等方法,这些方法的大体步骤如下:首先,使用不同手段生成一批固定数量且各不相同的队友策略;然后,训练智能体与这些生成的队友策略进行协作。
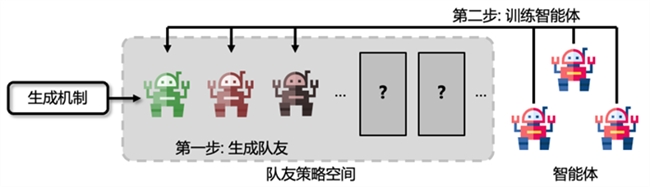
以往队友生成与训练智能体方法示意图
尽管这些方法在一些较为简单的协作场景中取得了一定的效果,但是这种分两步走、以队友策略生成模块为中心的训练范式仍然具有一定的局限性。第一,该范式需要提前指定需要生成的队友策略数量,然而最优的生成数量是无法提前得知的,过少的队友不足以覆盖策略空间,而过多的队友会降低训练效率。第二,该范式生成队友策略先于训练智能体,是以队友策略为中心的范式,然而,即使生成的队友各不相同,但从智能体的视角来看,它们的行为可能并不具有多样性,智能体只需要单一的协作模式即可与它们配合,这导致生成的队友并不能高效地覆盖策略空间。第三,该范式需要智能体同时与大量生成的队友学习协作,会导致增大训练难度。以上问题启发我们:开发一种新的以智能体为中心的训练范式,从智能体的视角持续高效地生成未见且多样的队友并学会与它们协作,直到智能体学会与策略空间中所有有代表性的队友协作,这样一来智能体就具备与任意队友协作的能力了。
与任意队友协作的学习算法:主动出击
为了达成上述目标,我们需要开发以智能体为中心的训练范式实现高效的队友生成与智能体训练,其中的核心思想是以持续学习的过程,主动地生成与智能体还协作得不够好的新队友与之训练,真正做到智能体视角中的队友策略多样性,并高效提升智能体的协作能力。
1、队友生成:以智能体为中心的多样性
该模块的目标是持续高效地生成多样的队友策略以逐步覆盖队友。受到基于种群的训练和演化算法的启发,我们维护一个队友策略种群并迭代地对其进行优化。
首先,每个队友策略需要具备基本的协作与完成任务的能力,以确保与智能体的配对训练是有意义的,为此队友策略需要与其自身的复制策略协作以最大化回报与完成任务,即最大化自博弈(self-play, sp)目标:
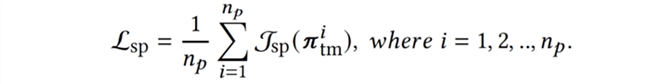
接下来,为了增强种群内队友策略的多样性,我们引入多样性(diversity)目标增大策略间的距离:
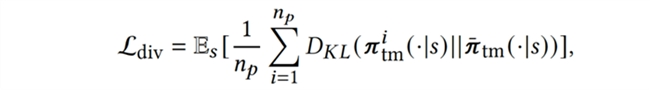
最后,为了主动地生成与智能体还协作得不够好的新队友与之训练,我们加入不相容性(incompatibility)目标,使队友策略最小化与智能体协作的回报,迫使队友寻找新的协作模式,覆盖策略空间的新区域,从智能体的视角高效地增强队友策略多样性:
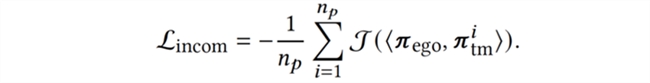
优化当前的队友策略种群同时最大化以上三个目标,即可得到一个新的队友策略种群与智能体进行配对训练了。
2、学智能体:持续学习防止遗忘旧队友
设计好队友生成模块后,我们可以持续地生成多样的队友策略用以训练智能体。由于将要生成的队友策略的数量是未知的,且为了节省算法的存储空间开销,我们无法存储所有已经生成的队友策略与智能体配对训练。为了防止智能体遗忘与过去生成队友协作的能力,我们使用了多任务头架构的多智能体持续协作技术[2]进行训练,既能使智能体快速学习与当前新生成的队友进行协作,又可以保持其与过去生成队友的协作能力。这样一来,算法只需要存储当前新生成的队友种群与智能体训练而不需要存储所有生成过的队友,在节省存储开销的同时提高了智能体的学习效率。
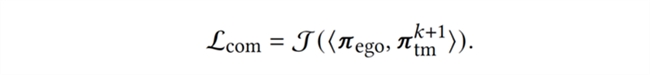
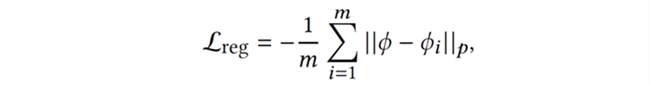
以上是训练智能体的两个优化目标,第一个目标旨在提高智能体与当前(第 k+1 轮)队友的协作能力,即相容性(compatibility);第二个目标是对智能体神经网络中的特征提取器部分进行正则化(regularization) 以缓解遗忘现象。
3、整体算法:交替进行直到空间全覆盖
介绍(a)队友生成模块与(b)智能体学习模块后,我们提出本工作的 Macop 整体算法。首先初始化第一代队友种群与智能体策略,随后交替进行(a)队友生成与(b)智能体学习,期间生成第二代、第三代等队友种群与更新智能体策略。该过程将持续进行到第 K 代队友种群在更新后依然无法降低与当前智能体协作的回报,即降低相容性失败。这说明,此时整个队友策略空间已经得到覆盖,且智能体已经学会与所有生成的队友协作。Macop算法则会终止并输出具有强大协作能力的智能体。
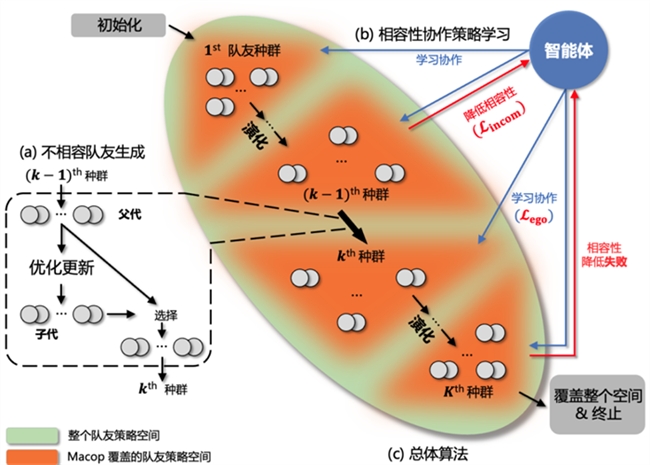
Macop整体框架示意图
技术验证
我们在食物收集、猎物追捕、合作导航、星际争霸微操四个环境的八个场景上对算法进行验证。
1、Macop 可以极大地提高智能体与不同队友协作的能力
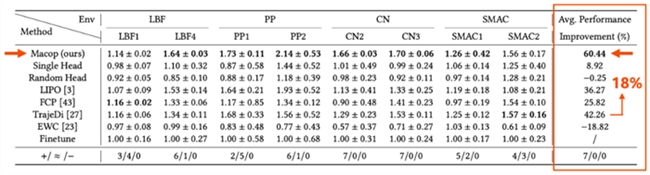
各个算法测试的队友策略相同,均为 Macop 与所有对比方法生成的队友策略的集合,也即每个算法的智能体都需要与大量未见队友进行协作。在各个任务场景中,相较当前致力于提高智能体与未见队友协作能力的方法与变种,Macop均表现出明显的回报优势。表格最后一列的平均性能提升指标显示,Macop更是比最好的对比算法提升高出 18%。
2、Macop可以很好地与未见队友进行协作
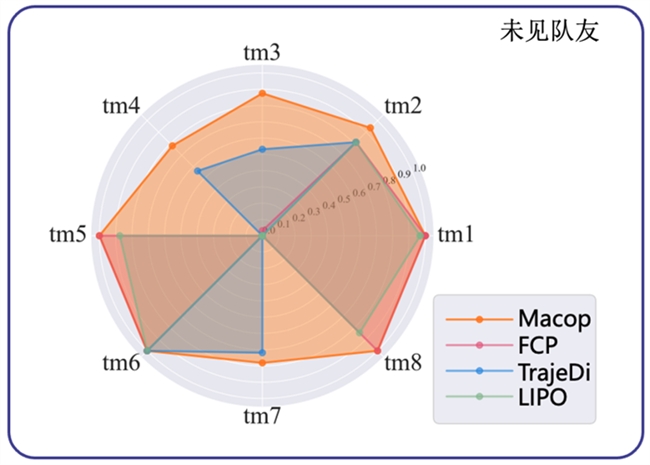
我们收集了八个所有算法的智能体都没有见过的队友策略(tm1~tm8)作进一步测试。测试回报的雷达图显示,相较于其他方法,Macop可以更好地与这些队友进行协作,验证了Macop的有效性。
结论
真实场景中智能体需要与各种未见队友策略进行协作,就需要智能体在训练阶段与尽可能多样的队友学习。本工作第一次真正站在智能体的角度持续生成这些需要的队友策略,如同为智能体提供一本“练级攻略”,有方向且高效率地提升自身的协作能力。
这一算法可以应用在高频变化的多智能体系统,也可以应用在人机交互的现实场景等,让这些懂得协作的智能体更好地服务我们的生产与生活。
免责声明:市场有风险,选择需谨慎!此文仅供参考,不作买卖依据。
相关阅读 换一换
-
中国小微特机器人创新发展大会成功举办,水陆空机器人现场炫技
5月8日,2024年中国小微特机器人大赛暨小微特机器人创新发展大会在
-
从“芯”出发:英特尔重塑PC计算模式,为制造业释放无限AI潜能
以OpenAI推出的ChatGPT为标志,生成式AI技术在全球不断掀起热潮,仅
-
蜀南竹海【宇宙猜想】飞行巴士——探索未知,寻梦江湖!
极目蜀南,凌渡竹海。蜀道虽难,必到蜀南,竹海且深,腾空凌渡。今
-
AKG重磅发布N5 Hybrid耳机|参考级音质与AI黑科技对撞,引爆降噪耳机新潮!
今日,全球知名音频品牌AKG发布旗下全新力作——N5 Hybrid真无线降噪耳机。该产品承袭AKG的高标准参考级音质,并融入全新的AI技术,再次彰
-
智能设备+创新模式,新北洋助力各行各业拥抱新质生产力
2024年开年伊始,国家就推出“大规模设备更新和消费品以旧换新”这
-
视比特“PaintPro漆面缺陷检测及自动磨抛修复系统”应用升级!
涂装工艺质量管控是汽车制造的关键环节之一,直接关乎汽车外观品质
-
“华为盘古”开天,“乐聚夸父”逐日,机器人产业应用迈向新纪元
3月15日,华为云与乐聚机器人在华为云&华为终端云创新峰会2024上签署
-
哈尔滨工业大学(深圳)成功举办InsunICC人工智能学术研讨会
2024年3月15日-16日Insun Intelligent Computing Conference(In
-
南栖仙策提出高相容性协作算法,保障智能体在开放环境中的高效协作
开放环境的机器学习是目前的研究难点与热点,是算法落地的关键之一
-
海尔、乐聚联手,发布国内首款家庭服务人形机器人
近日,乐聚机器人在全网了发布了一段人形机器人进入家庭干活的视频,
-
挚途科技荣获网络安全国标优秀实践案例一等奖
近日,由中国电子技术标准化研究院、中国汽车工业协会牵头,挚途科
-
南栖仙策获评2023中国人工智能行业领军企业
近日,由信息化观察网、中国软件和信息服务业年度风云榜组委会等单
-
深圳文交所参与发起成立“中国技术经济学会人工智能应用专业委员会”
2024年1月21日,首届人工智能应用大会暨中国技术经济学会人工智能应
-
「知其所以」特别篇 X四川观察|当科技更有温度,AI能否打破老年人的数字鸿沟?
不会扫码点餐、不会网上打车、不会网上缴费、不会视频聊天……科技
-
前瞻科技,国内首个人形机器人比赛发布
12月28日,第二十六届中国机器人及人工智能大赛人形机器人创新挑战赛
-
海研科技全面升级板材在线视觉检测系统,赋能志邦家居智能生产
近日,海研科技的第二套板材在线视觉检测系统已经正式发货至志邦工
-
为AI加速而生 英特尔第五代至强CPU带来AI新表现
AI时代,亲民、易用的CPU如何能实现相比GPU更具性价比的加速方案?
-
泛联信息亮相青年科学家创新发展大会,探索人工智能新未来
11月22日,首届主题为“青荟齐鲁·悦创泉城”的青年科学家创新发展
-
剑网3旗舰画质beta正式上线 年度资料片“万灵当歌”震撼公测
风擎山河势,意驭乾坤移,《剑网3》年度资料片“万灵当歌”今日正式
-
来酷科技半年报数字的背后 降本增效提速显著 经营质效双提升
春华秋实,不负耕耘。来酷科技2023年上半年战报发布。报告期内,来酷
推荐图片
 “水味贵甘,水质贵轻”,今麦郎软化纯净水邀你共同关注饮水健康
“水味贵甘,水质贵轻”,今麦郎软化纯净水邀你共同关注饮水健康
 金正大与京东达成战略合作 携手为农业全产业链赋能
金正大与京东达成战略合作 携手为农业全产业链赋能
热闻推荐
- 中国小微特机器人创新发展大会成功举办,水陆空机器人现场炫技
- 从“芯”出发:英特尔重塑PC计算模式,为制造业释放无限AI潜能
- 蜀南竹海【宇宙猜想】飞行巴士——探索未知,寻梦江湖!
- 智能设备+创新模式,新北洋助力各行各业拥抱新质生产力
- 视比特“PaintPro漆面缺陷检测及自动磨抛修复系统”应用升级!
- “华为盘古”开天,“乐聚夸父”逐日,机器人产业应用迈向新纪元
- 哈尔滨工业大学(深圳)成功举办InsunICC人工智能学术研讨会
- 南栖仙策提出高相容性协作算法,保障智能体在开放环境中的高效协作
- 海尔、乐聚联手,发布国内首款家庭服务人形机器人
- 挚途科技荣获网络安全国标优秀实践案例一等奖
- 南栖仙策获评2023中国人工智能行业领军企业
- 深圳文交所参与发起成立“中国技术经济学会人工智能应用专业委员会”